import sys
import time
import datetime
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import pandas
from bs4 import BeautifulSoup
import csv
def neomobile_login(neomobileusername,neomobilepassword):
# chromedriverは、chromeのバージョンに合わせて、常に最新にする
# chromedriver.exeの場所をフルパスで指定してください。
chromedriver = "chromedriverのフルパス"
driver = webdriver.Chrome(chromedriver)
# ネオモバログインHP
driver.get("https://trade.sbineomobile.co.jp/login")
# 3秒待つ
time.sleep(3)
user = driver.find_element_by_name("username")
passwd = driver.find_element_by_name("password")
btn_login = driver.find_element_by_id("neo-login-btn")
user.send_keys(neomobileusername)
passwd.send_keys(neomobilepassword)
btn_login.click()
# 1秒待つ
time.sleep(1)
return driver
def portfolio_list():
#ポートフォリオページにアクセス
driver.get("https://trade.sbineomobile.co.jp/account/portfolio")
time.sleep(2)
#最下部までスクロール
html01=driver.page_source
while 1:
#div class sp-main内をスクロール 参考https://ja.coder.work/so/java/853876
#スクロール幅10000pixelで設定しています。3ページ読み込み程度では問題なく動きますが、上手くいかないようなら数字を大きくしてみてください。
driver.execute_script("arguments[0].scrollTop =arguments[1];",driver.find_element_by_class_name("sp-main"), 10000);
time.sleep(2)
html02=driver.page_source
if html01!=html02:
html01=html02
else:
break
# 文字コードをUTF-8に変換
html = driver.page_source.encode('utf-8')
# BeautifulSoupでパース
soup = BeautifulSoup(html, "html.parser")
#table(現在値〜預り区分をpandasで取得)
table = soup.findAll("table")
df_table = pandas.read_html(str(table))
#table数(保持銘柄数)
tableno=len(df_table)
#空のデータフレームを作成
list_df = pandas.DataFrame( )
#銘柄ごとにテーブルを取得し追加していく
for x in range(0,tableno):
s=df_table[x].iloc[:,1]
list_df=list_df.append(s)
#列名の付け直し
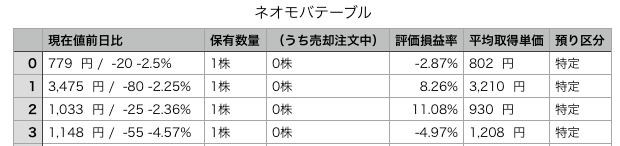
list_df.columns=['現在値前日比','保有数量','(うち売却注文中)','評価損益率','平均取得単価','預り区分']
#indexを0から振る
list_df=list_df.reset_index(drop=True)
print("テーブル抽出")
list_df.to_csv("ネオモバテーブル.csv")
#コード、銘柄名、評価額、評価損益はclass名から1銘柄ずつ取得する
#コード
code_list=list()
for codes in soup.find_all(class_="ticker"):
code=codes.get_text()
code=code.strip()
code_list.append(code)
df_code=pandas.Series(code_list)
#銘柄名
name_list=list()
for names in soup.find_all(class_="name"):
name=names.get_text()
name=name.strip()
name_list.append(name)
#print("銘柄名")
#print(name)
df_name=pandas.Series(name_list)
#評価額
value_list=list()
for values in soup.find_all(class_="value"):
value=values.get_text()
value_list.append(value)
df_value=pandas.Series(value_list)
#評価損益
rate_list=list()
for rates in soup.find_all(class_="rate"):
rate=rates.get_text().strip()
rate_list.append(rate)
#print(fUp)
df_rate=pandas.Series(rate_list)
#コード〜評価損益を結合
df=pandas.concat([df_code,df_name,df_value,df_rate],axis=1)
#列名を更新
df.columns=['コード','銘柄名','評価額','損益']
df_result=pandas.concat([df,list_df],axis=1)
df_result.index=df_result.index+1
#出力確認用
#df_result.to_csv("ネオモバポートフォリオ.csv")
#数値を扱いやすいように修正
#評価額
value=df_result["評価額"].str.split("\n",expand=True)[1]
value=value.str.replace(',','')
print(value)
#損益
rate=df_result["損益"].str.split("\n",expand=True)[1]
rate=rate.str.replace(',','')
print(rate)
#現在値
price=df_result["現在値前日比"].str.split(" 円",expand=True)[0]
price=price.str.replace(',','')
#前日比円
pricerate=df_result["現在値前日比"].str.split("/ ",expand=True)[1]
pricerate=pricerate.str.split(" ",expand=True)[0]
pricerate=pricerate.str.replace(',','')
#前日比パーセント
pricepercent=df_result["現在値前日比"].str.split("/ ",expand=True)[1]
pricepercent=pricepercent.str.split(" ",expand=True)[1]
pricepercent=pricepercent.str.split("%",expand=True)[0]
#保有数量
stock=df_result["保有数量"].str.split("株",expand=True)[0]
stock=stock.str.replace(',','')
#売却注文中
stocksell=df_result["(うち売却注文中)"].str.split("株",expand=True)[0]
stocksell=stocksell.str.replace(',','')
#評価損益率
percentage=df_result["評価損益率"].str.split("%",expand=True)[0]
#平均取得単価
aveprice=df_result["平均取得単価"].str.split(" ",expand=True)[0]
aveprice=aveprice.str.replace(',','')
#データフレームを結合
df_result2=pandas.concat([df_result["コード"],df_result["銘柄名"],value,rate,price,pricerate,pricepercent,stock,stocksell,percentage,aveprice,df_result["預り区分"]],axis=1)
df_result2.columns=['コード','銘柄名','評価額(円)','損益(円)','現在値(円)','前日比(円)','前日比(%)','保有数量(株)','(うち売却注文数)(株)','評価損益率(%)','平均取得単価(円)','預り区分']
return df_result2
def export_data(df_result, name):
df_result2.to_csv(name + '{0:%Y%m%d}.csv'.format(datetime.date.today()))
if __name__ == '__main__':
# SMBC日興ログインアカウント
neomobileusername = "ユーザーネーム"
neomobilepassword = "パスワード"
name="SBIネオモバイルポートフォリオ(csv出力時のファイル名)"
#ログイン
driver=neomobile_login(neomobileusername,neomobilepassword)
#注文中リストの書き出し
df_result2=portfolio_list()
export_data(df_result2,name)
driver.quit()



 管理人みゆき
管理人みゆき
 管理人みゆき
管理人みゆき





コメント
コメント一覧 (1件)
[…] https://3daysam.com/neomobaportfoliotocsv/#toc4 […]